Deep Dive: Building a Kubernetes Operator SDK for Java Developers
Java-operator-sdk allows developers to implement Kubernetes operators in a simple and convenient way. In this post I will give insight into the challenges of implementing operators and how the framework solves them.

Operators in a Nutshell
Kubernetes provides an extension mechanism by allowing us to define our own resource types, called custom resources. Running a pod on the cluster that monitors a type of custom resource and manages other resources based on it, is the Operator pattern.
As the official Kubernetes documentation says, ‘‘Operators are clients of the Kubernetes API that act as controllers for a Custom Resources’.
Here’s a sample custom resource:
apiVersion: "sample.javaoperatorsdk/v1"
kind: WebPage
metadata:
name: hello-world-page
spec:
html: |
<html>
<head>
<title>Hello Operator World</title>
</head>
<body>
Hellooooo Operators!!
</body>
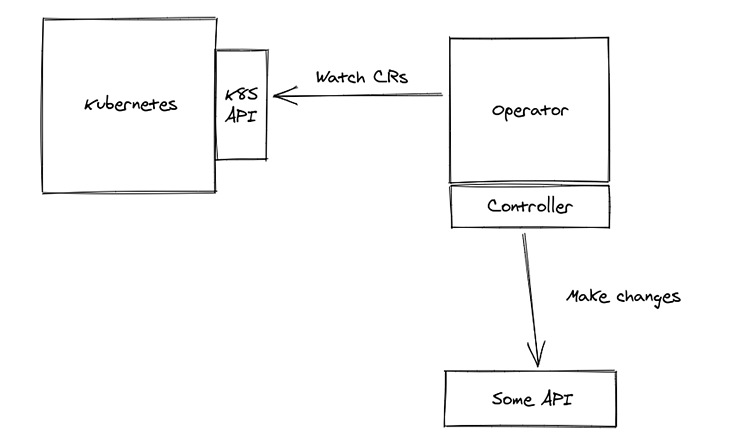
</html>In other words, an operator just connects to the Kubernetes API, to watch for events related to custom resources. Based on these events, we execute controllers. Controllers provide the implementation that makes sure we reconcile with the target domain. Note that, by watching the event, we receive the whole resource as the event payload. Thus, we receive a declarative description, which defines how our target domain object should look. In the controller we take the whole custom resource, more precisely the .spec part of it, and we translate the declarative description to imperative actions, usually API calls of the target system (which can be the Kubernetes API or any other).
Building an SDK
We decided to create the java-operator-sdk to solve certain common problems that every operator written in Java will need to tackle. When we started to work on our first operator, it was really just a thin wrapper around the fabric8 Kubernetes API client. The two main topics that we tackled later are: how to efficiently handle events and how to manage consistency. The problems in these categories (which are not unrelated) are not trivial, but can be solved by a framework. This means developers won’t have to worry about these concerns anymore, and creating an operator would mean just implementing a simple interface.
Event Scheduling
When we watch for events in Kubernetes we receive them serially on a single thread. More precisely all the events for a custom resource type — or a ‘watch’ in Kubernetes terms. We want an efficient multithreaded way to process these events. At the end we defined these three essential requirements for the event-scheduling algorithm:
1. Concurrently processing events for different resources.
A controller execution can take very long. For example, we had controllers that literally took minutes because of slow responses from remote APIs, while incoming events for different resources (of the same type) are not related. That’s why we don’t want to process them one by one in a serial way. When we receive a new event, we schedule it using an executor service with a given thread pool, and make the processing concurrent.
2. Serial event processing for a single custom resource.
On the other hand we don’t want to execute events concurrently for the same resource. Imagine the situation: when we change a custom resource we start execution of a controller for the event, but someone suddenly changes the resource again. This would lead to a new event and a new controller execution. Although this would not lead to a classic race condition in terms of shared memory between the threads, there will be two threads which are calling all kinds of APIs in an arbitrary order. In corner cases, it could even happen that the later event gets processed faster than the first one, resulting in an inconsistent state.
What we want here is for events of the same resource to execute serially — one after another. Thus, we should start new event processing only if the previous one gets finished. Note that if we start processing the event, we can receive an arbitrary number of new events for the same resource (meanwhile, an arbitrary number of changes can be applied to a custom resource). However, since the payload of an event is the whole resource, we can just discard all of them except the last one, which will be the most recent.
3. Retrying failed controller executions
‘Everything fails, all the time’.
— Werner Vogels, CTO, Amazon.com
In that case, we might want to retry. More specifically the framework can retry the call to the controller, when the reconciliation logic fails. It can retry the call usually at least once, in case of a network error. To achieve this, we maintain an in-memory state — the number of retries already executed for a particular event. The limit of retries, back-off period, or time limits are all configurable. This complicates the scheduling a bit, since we have a number of additional scenarios.
For example: imagine we receive new events while we have an exception in the controller. In this case, we don’t want to retry; just discard the failed event, and process the new one.
Fortunately the different scenarios can be quite nicely handled in the code, and we were happy at the end that the scheduling algorithm became simple enough.
The ‘Generation’ Metadata Attribute
Kubernetes objects have a metadata attribute called ‘generation’. This is a number that increments on every change, excluding changes on .metadata and .status sub-resource. If we receive a new event, but the generation did not increase, we could just ignore that event and should not execute the controller. Remember that, in controller implementation, our main concern should be the .spec part.
To implement scheduling that is aware of generation, we can maintain a simple in-memory state with the highest generation we processed and/or received within an event. If the generation of a new event is not higher, we can discard it.
This is a nice optimisation, but it still might happen that the controller implementation depends on metadata, or on a status field. Note that this is a framework, so by applying the YAGNI principle, we might miss some actual use cases. Therefore, we followed the ‘some might need it’ principle, by introducing a flag on controller level, which can turn off generation-based event filtering. Thus, the controller will receive all the events for all the changes.
Consistency
We are dealing with an event-driven distributed system. The characteristics and guarantees that Kubernetes API provides already help us a lot with event processing, as well as the event scheduling we discussed above solves many issues. We still have to deal with some additional ones to manage consistency:
‘At Least Once’ and Idempotency
The controller implementation should be idempotent. The reason is that we cannot guarantee exactly-once processing of an event—even if retries are turned off. In other words we are dealing with an ‘at least once’ guarantee here.
It can happen in surprisingly many scenarios that we will process an event multiple times — typically, when the operator crashes during an execution of the controller. Thus, a controller is processing the event; before the end of processing the process/pod gets killed. After a restart, it will just simply process the last event again. By making the controller implementation idempotent, the issue is solved in an elegant way.
Deleting Resources and Finalizers
Kubernetes finalizers help us make sure we don’t lose a delete event. Picture a situation where an operator crashes or isn’t running while a custom resource gets deleted. When we start to watch for events, we won’t get delete events for resources deleted earlier. So after the operator starts, we wouldn’t receive the delete event. We would end up in an inconsistent state.
To avoid this problem, we automatically add finalizers when we first receive an event for a custom resource. This will ensure that the resource won’t be deleted until we remove the finalizer — thus, before we execute the deletion-handling method. We add finalizers in all cases, even if a controller does not instruct us to update the resource. In other words, after the controller execution we check if the custom resource has the target finalizer; if not, we add it and update the resource. This might seem to be an opinionated approach but, without finalizers it’s just not possible to guarantee delete-related consistency.
There is a one corner case scenario when even this is not enough: we receive a ‘create event’, execute the controller, but for some reason we are not able to add the finalizer (this is the first run), or the operator crashes before we can add the finalizer. At this moment somebody deletes the resource. At the end of this scenario, all the resources were going to be created by the controller, but since there was no finalizer, the custom resource does not exist anymore. Fortunately, this is something that rarely happens in practice.
The Lost Update Problem and Optimistic Locking
Custom resources can be updated using the Kubernetes API at any time. In addition to that, at the end of an event processing we might want to write back some changes to the custom resource — meaning the operator will do an update, too.
So, imagine a scenario when we are processing an event, and we want to apply an update on the custom resource (like adding some annotation defined by the controller). However, just before that, an API user also changes the custom resource. Since by making the update we replace the whole resource, this could result in a lost update, which was made by the API user. This is a classic scenario of the ‘lost update problem’.
The solution is to use optimistic locking, which means we only do conditional updates on the resource at the end of the processing, thus checking to make sure the resource didn’t change after we started to process it. If yes, we don’t update the resource; more precisely we will receive a ‘conflict’ error from the Kubernetes API. This is not a problem since we will receive and process the event anyway, from the update that happened while the controller was executing.
For this reason, if we apply changes to resources from the controller, conflicts will naturally happen. This might be a bit strange, but this is an efficient way to handle these scenarios.
Run Single Instance
We should always run a single instance (think pod) of an operator. If there were multiple instances of the same operator running (and listening to events from the same set of resources) we would have similar issues like we already discussed in point 2 of the Event Scheduling section. Two processes would receive the same event, so there would be two separate processes making changes in arbitrary order based on the same custom resource specs.
Note that there are ways to cope with this problem, like pessimistic locking. None of these are trivial with the current setup of Kubernetes. So the pragmatic solution here is to just run a single instance.
What About Downtime?
What happens if the pod of the operator crashes? Kubernetes will restart it, and when we register the watch we receive the most recent events of all the resources again. In this way we also process events of changes that were done while the operator was not running.
Note that this is not optimal. We would probably just want to process the events we missed, while an operator was down. Unfortunately this isn’t possible without persisting state — saving the last processed resourceVersion for every resource. This might be nice, but it’s not a trivial optimization and for now we decided not to implement it.
Conclusion
Hope you now have a taste of the core problems the framework has to deal with. There are also more enhancements and features on the way. Please let us know if you have any questions or feedback.
Photo by Jeremy Bishop on Unsplash
